OBSERVEOPS
Service Level Objectives
From availability to performance, from error budgets to burn rates, assuring clarity, control, and consistency for the services your business depends on.
Motadata ObserveOps SLO provides a unified framework to define, measure, and optimize reliability. Track availability and performance across monitors, links, servers, applications, and business services. Understand where budgets burn, where failures originate, and where improvement matters most — all from one intelligent, correlated platform.
Core Features
Built for Reliability, Accountability, and Control
Service level management that transforms metrics into measurable commitments — giving you complete clarity on how your services perform against business expectations.
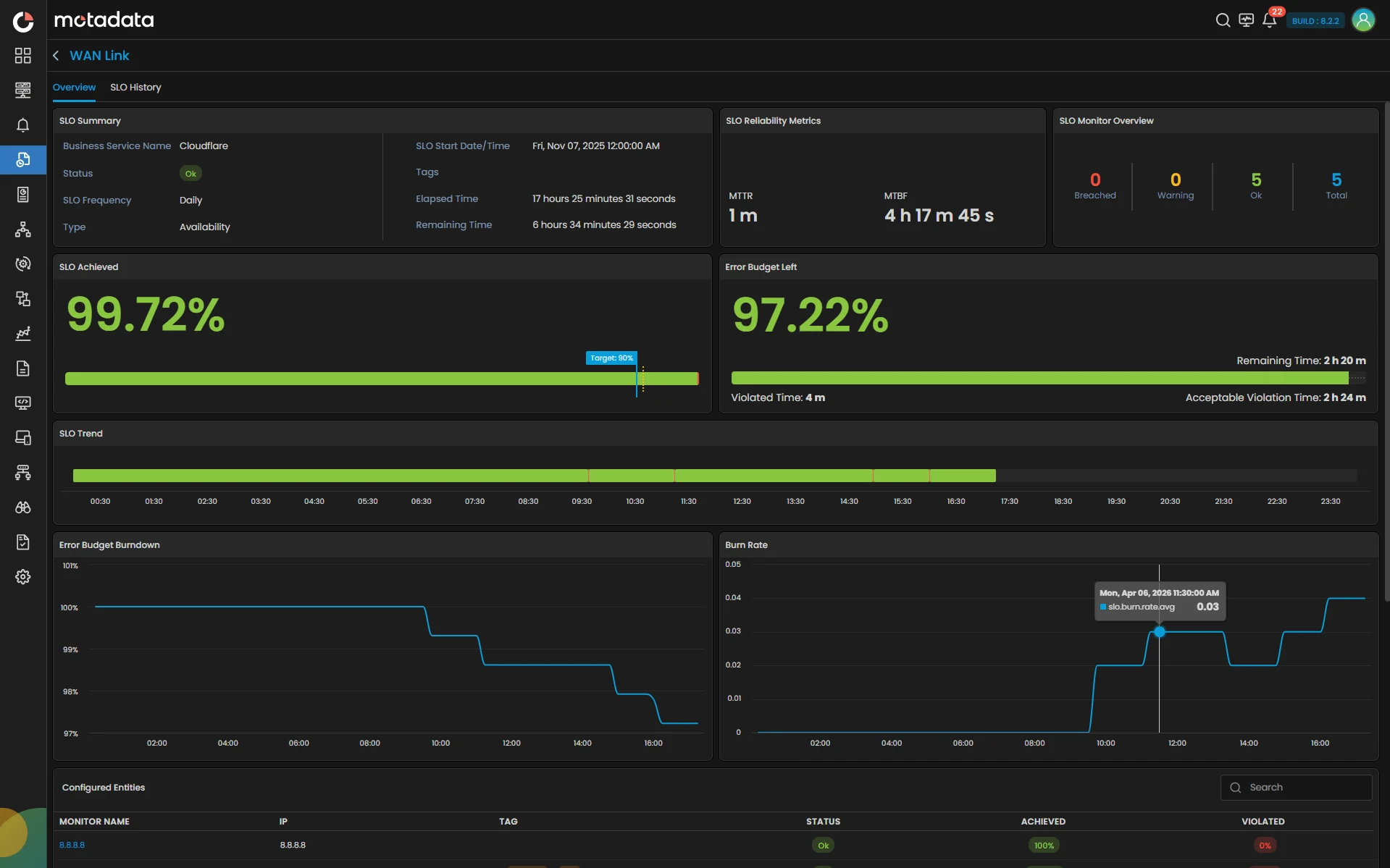
Unified Service Reliability Tracking
Define and monitor availability, performance, and event-based SLOs across infrastructure, applications, and business services.
Business-Aligned Service Objectives
Map technical performance to real business services, ensuring reliability is measured where it truly matters.
Error Budget Intelligence
Understand how much reliability margin remains and how quickly it is being consumed with real-time burn rate visibility.
Granular Contribution Visibility
Drill down from service-level SLOs to individual components to identify exactly what impacts overall performance.
Compliance & Governance Clarity
Track adherence to internal SLAs and external commitments with structured policies, reporting, and audit-ready insights.
Operational Correction & Fairness Control
Apply corrections, exclusions, and penalties to reflect real-world conditions such as maintenance windows or external dependencies.
Every Service. Every Objective. Complete Reliability Clarity.
Capabilities
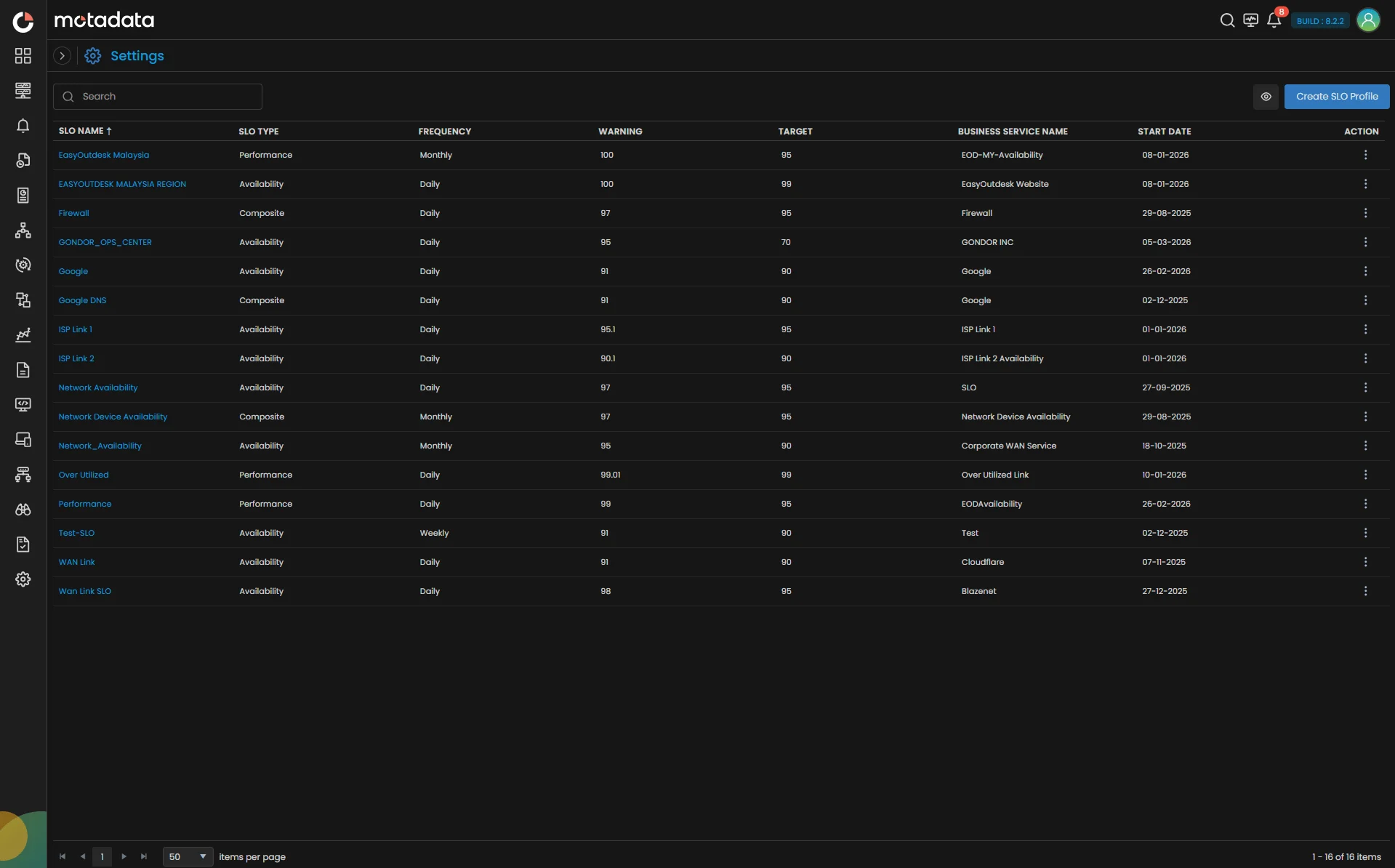
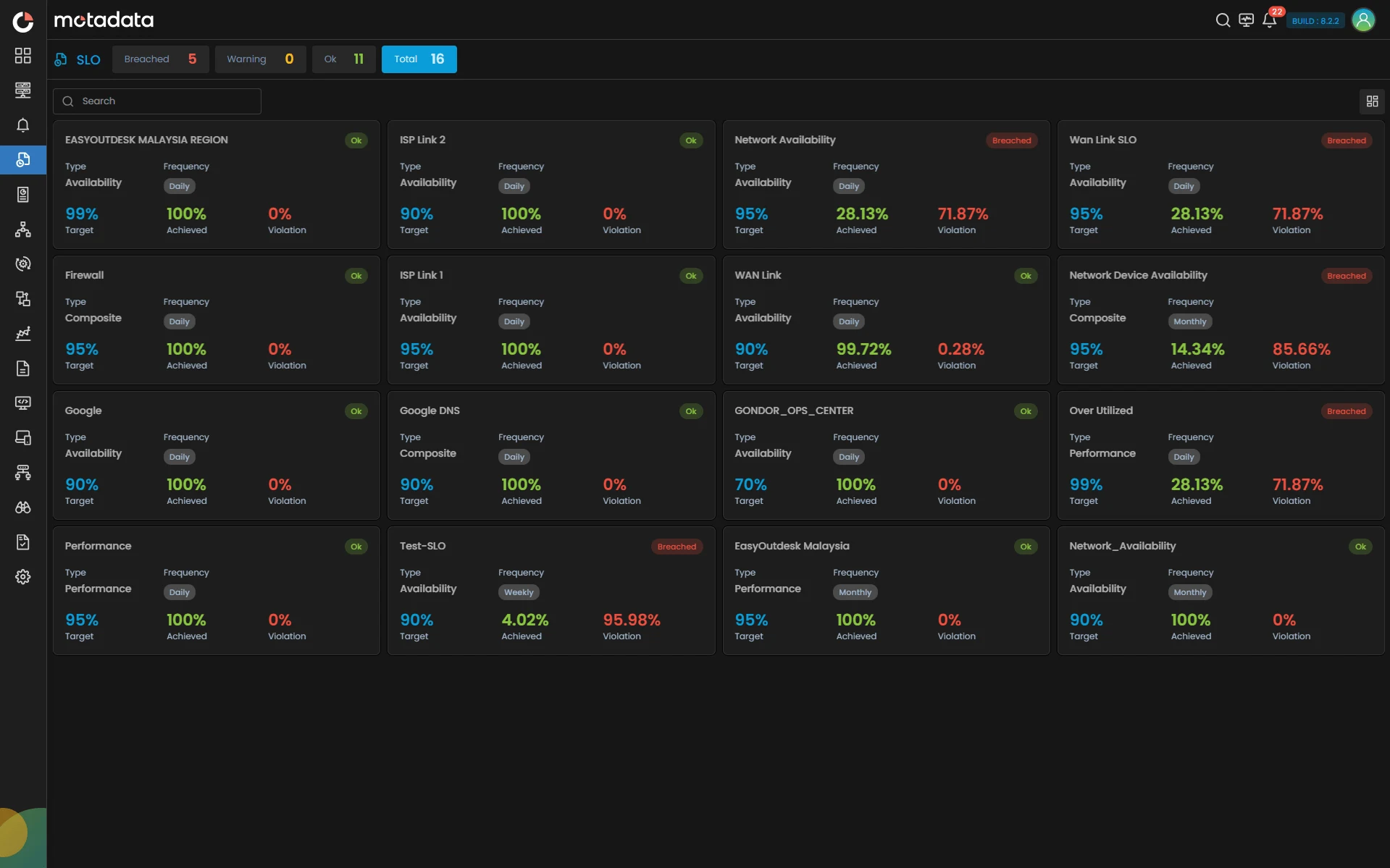
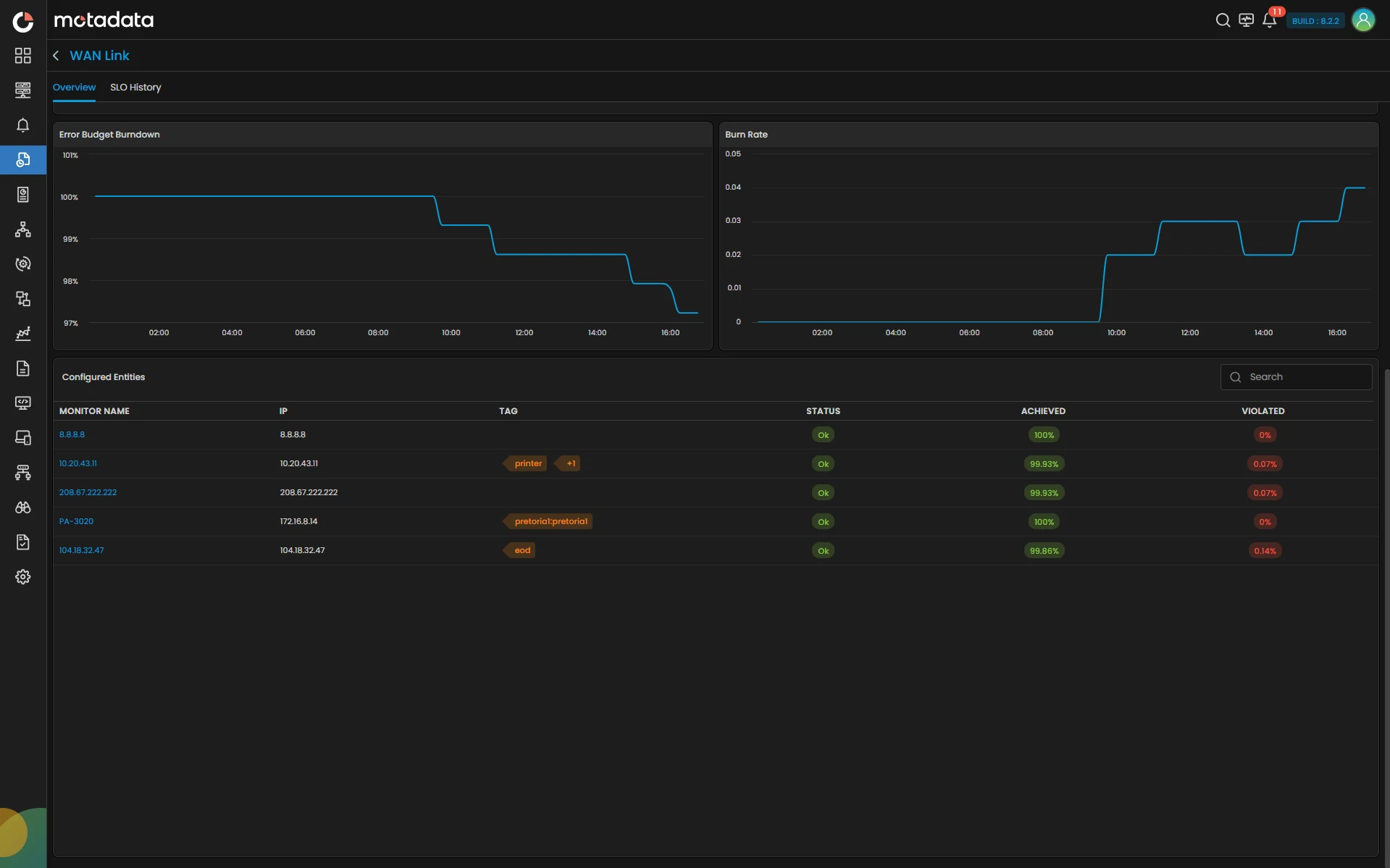
SLO Capabilities
Complete Hybrid Infrastructure Intelligence
Create Availability, Performance, and Event-based SLOs that reflect your real-world service commitments, not abstract metrics.
Key Highlights
- Availability SLOs: Monitors, network links, servers, applications, and composite business services tracked.
- Performance SLOs: Response time, throughput, latency, and custom KPIs measured against targets.
- Event SLOs: Compliance measured against specific operational rules or thresholds.
- Flexible Target Windows: Rolling, calendar, and custom windows aligned with business cycles.
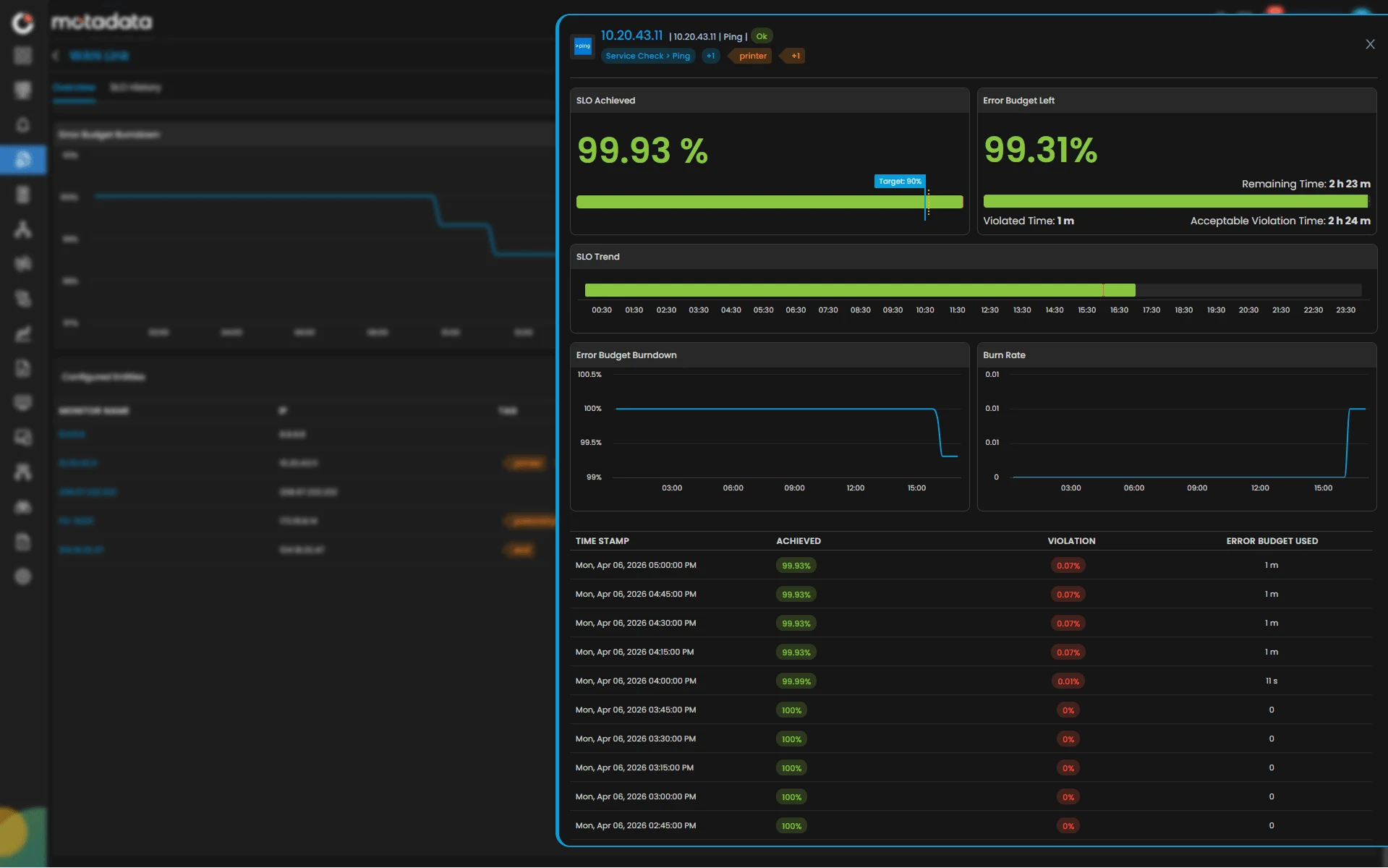
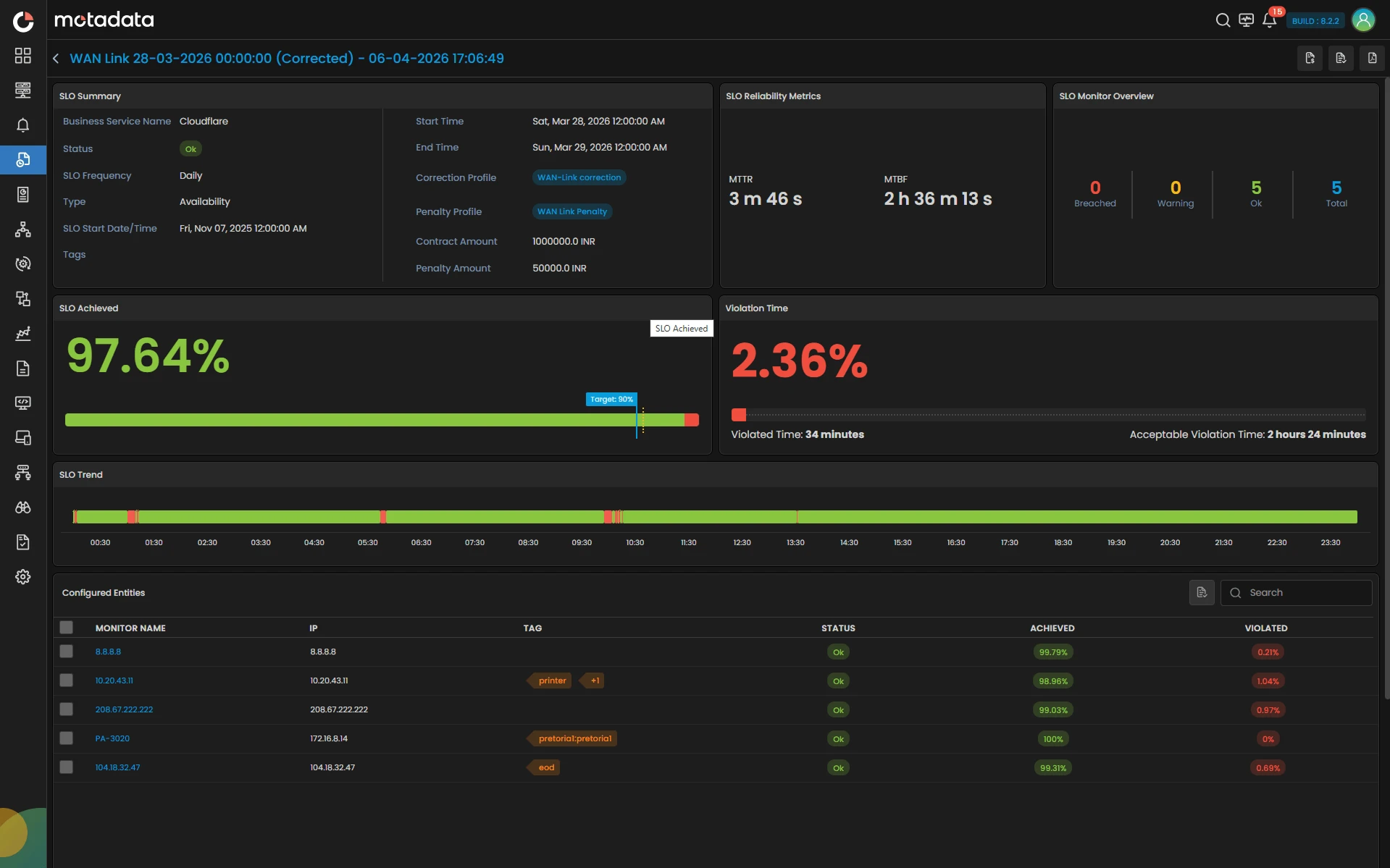
Define What Matters. Measure What Matters.
Metrics & Differentiation
0%
fewer false SLO breaches through intelligent corrections and dependency mapping.
0%
Faster RCA for SLO failures with entity-level contribution analysis.
0%
Stronger reliability governance for business and customer-facing services.
““Motadata SLO turned our reliability reviews into clear, data-backed conversations. We finally know where we’re burning and why.””
Rajesh Menon
— Director of Service Reliability, Telecom Enterprise
Why Motadata
Why Motadata Leads
From Infrastructure to Intelligence — Motadata Powers Unified Performance.
Cross-domain correlation
combining logs, traces, metrics, and topology for accurate SLO evaluation.
Powered by Motastore
for high-speed, long-window SLO analysis at enterprise scale.
Full business-service mapping
that reflects real user and business impact.
AI-driven burn-rate prediction
to prevent breaches before they occur.
Designed for hybrid environments
cloud, on-prem, and distributed architectures.
Enterprise Ready
Unified Visibility for a Hybrid, High-Velocity Enterprise
One platform to understand every system, every workload, and every environment — delivering clarity that scales, intelligence that adapts, and performance that endures.
Full-Stack Insight Across Hybrid & Multi-Cloud Environments
Enterprises run workloads be it datacenters, private cloud, public cloud, containers, Kubernetes, and converged systems. Motadata delivers unified insight across all of them, eliminating visibility gaps that create operational risk. IT Directors and SRE Leaders gain a single, authoritative view of every layer, regardless of where or how it runs.
Enterprises run workloads be it datacenters, private cloud, public cloud, containers, Kubernetes, and converged systems. Motadata delivers unified insight across all of them, eliminating visibility gaps that create operational risk. IT Directors and SRE Leaders gain a single, authoritative view of every layer, regardless of where or how it runs.
Predictive Intelligence for Capacity & Performance Planning
Modern infrastructure must anticipate demand, not react to it. Motadata’s AI-based forecasting highlights capacity saturation, resource drift, and performance risks long before users notice them. CIOs gain strategic foresight, enabling proactive investment planning and prevention of service degradation.
Modern infrastructure must anticipate demand, not react to it. Motadata’s AI-based forecasting highlights capacity saturation, resource drift, and performance risks long before users notice them. CIOs gain strategic foresight, enabling proactive investment planning and prevention of service degradation.
Vendor-Neutral Coverage for Complex Enterprise Ecosystems
Large organizations rely on a diverse mix of technologies — legacy servers, virtualized environments, HCI, SAN/NAS storage, multiple clouds, and container orchestration. Motadata supports them all with vendor-agnostic depth: Dell EMC, HPE, Hitachi, Huawei, NetApp, VMware, Nutanix, Hyper-V, Kubernetes and more. This gives enterprises freedom to evolve their architecture without losing observability continuity.
Large organizations rely on a diverse mix of technologies — legacy servers, virtualized environments, HCI, SAN/NAS storage, multiple clouds, and container orchestration. Motadata supports them all with vendor-agnostic depth: Dell EMC, HPE, Hitachi, Huawei, NetApp, VMware, Nutanix, Hyper-V, Kubernetes and more. This gives enterprises freedom to evolve their architecture without losing observability continuity.
Automation & Correlation for High-Efficiency Operations
Hybrid environments generate noise without context. Motadata applies correlation across metrics, logs, traces, storage, cloud and compute, then uses runbook automation to resolve recurring issues autonomously. NOC teams reduce toil, incidents resolve faster, and operations scale without scaling effort.
Hybrid environments generate noise without context. Motadata applies correlation across metrics, logs, traces, storage, cloud and compute, then uses runbook automation to resolve recurring issues autonomously. NOC teams reduce toil, incidents resolve faster, and operations scale without scaling effort.
Industry Solutions
Industry-Proven Infrastructure Solutions
Tailored for Your Infrastructure Challenges
BFSI
Guarantee real-time visibility across trading, core banking, and digital payments — ensuring compliance, security, and always-on service.
Telecom
Monitor multi-gigabit networks, correlate NetFlow data with subscriber QoE, and prevent outages before they scale.
Healthcare
Safeguard critical patient systems and comply with HIPAA through secure, low-latency observability.
Government & Public Sector
Achieve transparency, security, and control with on-premise observability supporting strict data sovereignty.
Manufacturing
Integrate IT and OT data to prevent production downtime and improve predictive maintenance accuracy.
Retail & eCommerce
Deliver frictionless digital experiences, monitor transactions in real time, and optimize site reliability at global scale.
ObserveOps Platform
Continue Your ObserveOps Journey
Unify every signal. Correlate every insight. Perform without compromise.
Network Observability
Unite flows, packets, and paths into real-time clarity with intelligent alerting at scale.
Network Configuration & Compliance Management
Automated config backups, compliance checks, and drift detection across your network.
Hybrid Infrastructure Monitoring
Monitor on-premise, cloud, and hybrid environments with unified visibility, AI-driven alerts, and real-time insights.
Log Monitoring
Cut through endless logs to reveal root cause with search, correlation, and analytics.
Application Performance Monitoring
Trace every transaction from frontend to backend with distributed tracing and service mapping.
Real User Monitoring
Capture every click and page load with web vitals, experience scores, and session replay.
FAQ
Frequently Asked Questions
Find answers to common questions about Infrastructure Monitoring and our capabilities.
A Service Level Objective (SLO) is an internal reliability target that defines the acceptable performance threshold for a specific service — such as 99.9% availability or a maximum response time of 200ms. An SLA (Service Level Agreement) is the formal contractual commitment made to customers or stakeholders, often with financial penalties for breach. SLOs act as the internal guardrails that teams manage proactively to ensure SLAs are never violated. Motadata ObserveOps SLO bridges both — giving IT and SRE teams the precision to define, track, and optimize reliability targets before they ever become contractual issues.