All Features
Network Observability
Network Anomaly Detection
Detect unusual behavior across network devices, traffic, and logs before your users notice. Motadata ObserveOps applies AI and ML baselining to your network metrics, then alerts your team when live values move outside the expected range.
What Is Network Anomaly Detection?
Network anomaly detection is the practice of spotting behavior in network metrics that falls outside a normal, learned pattern. It watches values such as device CPU utilization, interface traffic, response times, and error rates, then flags points that break from history. The aim is to catch a developing problem while it is still small.
An anomaly can point to a performance issue or a security event. Passive attacks quietly read and copy sensitive data. Active attacks go further and modify, encrypt, or delete it.
Both leave a trace in network activity well before the damage becomes obvious to anyone watching a dashboard.
Why Static Thresholds Miss Network Anomalies
Static thresholds miss network anomalies because they only fire when a fixed number is crossed. An admin sets a limit on a critical metric, and the system alerts once the value breaches it. Anything unusual that stays under the limit goes unreported.
That approach catches outright failures and little else. A slow drift in bandwidth use, a traffic pattern that shifts at an odd hour, or an error rate climbing steadily below the ceiling all pass through unnoticed.
Motadata ObserveOps builds its expectation from each metric's own history rather than a number you picked last year. It compares live values against that learned range and raises an alert when the gap is wide enough to matter. This is the difference between waiting for a failure and running proactive network monitoring.
How Motadata ObserveOps Detects Network Anomalies
Motadata ObserveOps detects network anomalies by building a baseline for every monitored metric and comparing incoming data against it. Baselining is the process of learning what a metric normally does across hours, days, and weeks. Values outside that learned range become candidates for an alert.
The platform works on network metrics, log data, and flow data from the same engine, so a single policy model covers device health, traffic behavior, and application response together.
1. Baselining Algorithms: Basic and Agile
ObserveOps offers two algorithms for analyzing pattern behavior in your metrics: Basic and Agile. You pick one per metric, set an acceptable deviation value, and the platform builds the expected band from there.
Basic suits metrics that move within a steady range. It draws a wider, smoother band around normal behavior and flags values that break out of it.
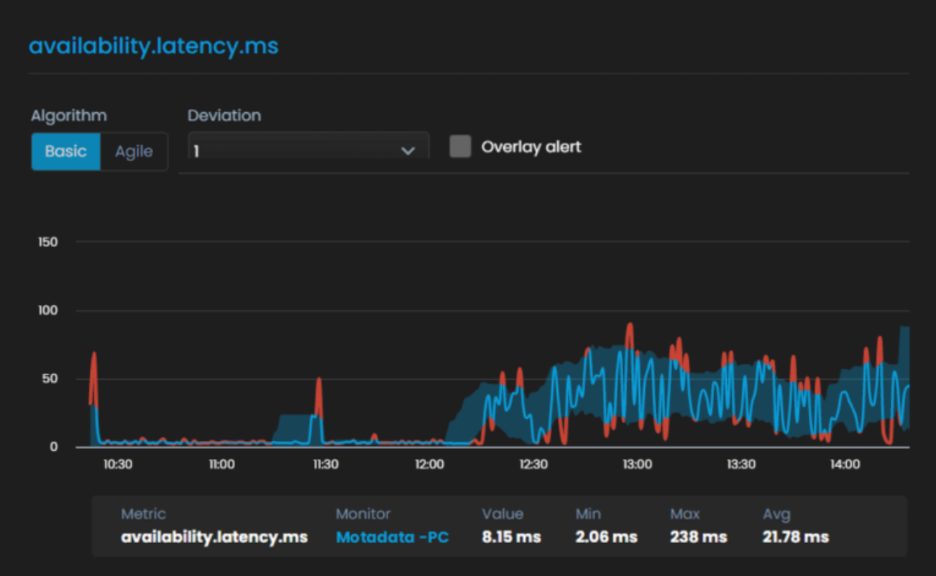
Agile suits metrics with strong daily or weekly cycles, where normal at 3 AM looks nothing like normal at 3 PM. It tracks the shape of the curve more closely, so a spike that would pass under a flat band still gets flagged.
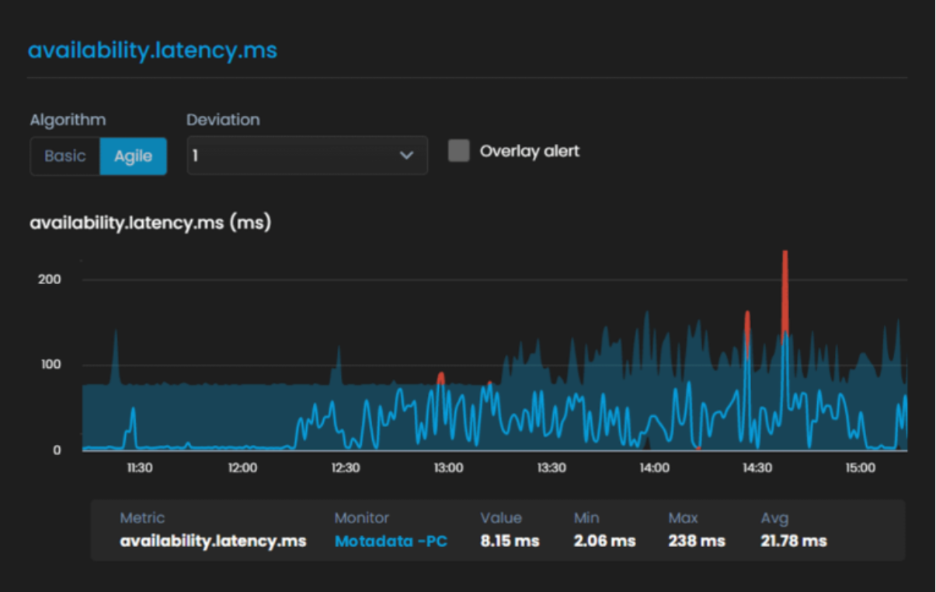
Choose the algorithm that matches the metric before you switch detection on. Start by identifying the use case and the type of network operation the metric represents. ObserveOps then forecasts expected behavior for that metric from its own history and compares live polled values against the forecast.
2. Polling Data Required Before Detection Starts
Each monitored metric needs a minimum of eight hours of polling data before the anomaly policy can work. That window gives the alert engine enough history to establish a baseline and work out an acceptable range for the metric.
The engine consolidates polling values into one sample point every half hour. Values falling outside the acceptable range are treated as anomalous and may trigger an alert once the remaining policy conditions are met.
3. Sample Lookup and Evaluation Frequency
The Sample Lookup field controls how many recent samples the anomaly policy reads at each evaluation. Setting it to 30 tells the policy to weigh the last 30 samples. AI and ML policy evaluation runs every 15 minutes.
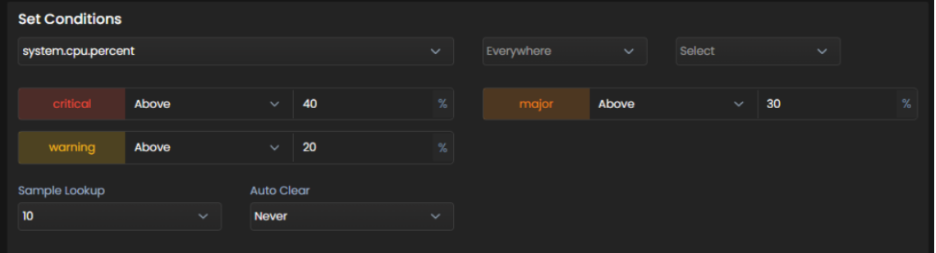
You build this on the Create Policy screen. Pick the metric, set the percentage band for each severity, then set Sample Lookup and Auto Clear.
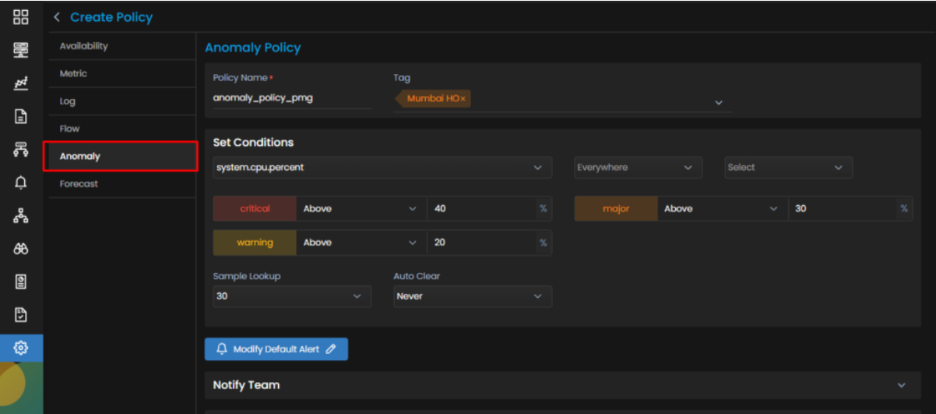
Anomaly policies work best on metrics with strong trends and recurring patterns, which is exactly where threshold alerting struggles most.
Understanding Anomaly Detection Through Use Cases
Alert severity is set by the share of samples in the lookup window that come back anomalous. You define the percentage band for each severity, and ObserveOps matches the count against those bands at every evaluation.
The four scenarios below all use the same policy. Sample Lookup is set to 10, critical fires above 40 percent of samples, major above 30 percent, and warning above 20 percent.
Against a lookup of 10 samples, those percentages work out to a straight count:
Critical: 5 or more of the last 10 samples are anomalous.
Major: 4 of the last 10 samples are anomalous.
Warning: 3 of the last 10 samples are anomalous.
No alert: fewer than 3 samples are anomalous.
Banding severity this way keeps minor variation out of the critical queue, which is one of the practical routes to alert noise reduction.
In each timeline below, N marks a non-anomalous sample and A marks an anomalous one. The shaded band is the Sample Lookup window the policy evaluates.
Scenario 1: Critical Alert
Five of the ten samples in the lookup window come back anomalous. That crosses the 40 percent band, so ObserveOps raises the alert at critical severity. 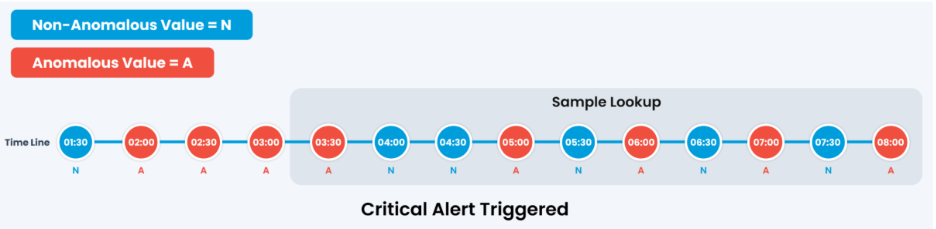
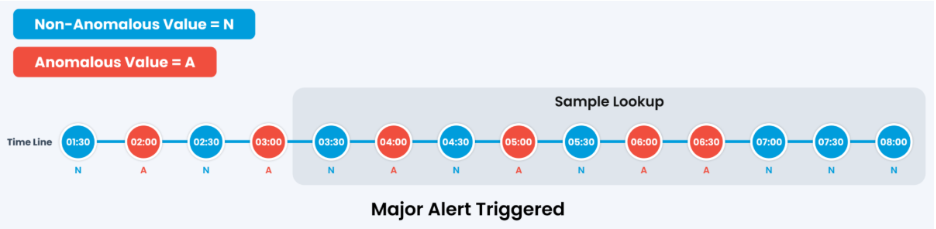
Scenario 2: Major Alert
Four of the ten samples come back anomalous. That clears the 30 percent band without reaching 40 percent, so the alert is raised at major severity.
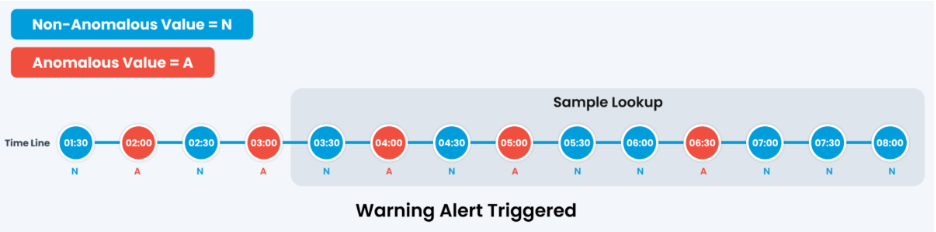
Scenario 3: Warning Alert
Three of the ten samples come back anomalous. That clears the 20 percent band only, so the alert is raised at warning severity.
Scenario 4: No Alert
Only one sample in the lookup window comes back anomalous. The count stays under every configured band, so nothing reaches the alert queue.
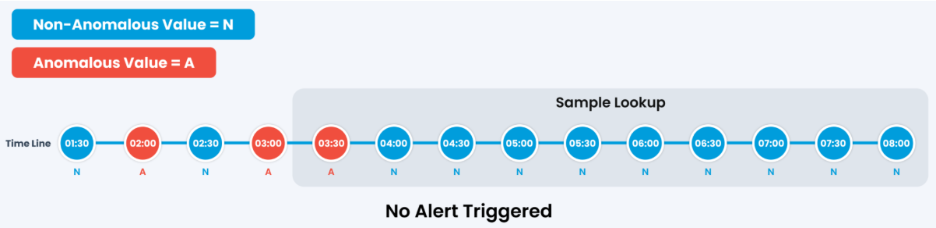
This is what keeps a one-off spike from paging anyone. The policy waits for a pattern across the window before it decides something is wrong.
Predictive Analysis for Network Capacity and Performance
Predictive analysis uses historical network data and statistical models to forecast what a metric will do next. Anomaly detection reports what is off right now. Forecasting projects what your links, interfaces, and devices will need weeks ahead.
ObserveOps applies the same learned history to network capacity planning. It surfaces interfaces trending toward saturation and devices heading for resource exhaustion, so teams can add bandwidth before network congestion builds.
That gives your team a window to plan the change during business hours instead of handling it as an incident.
What Network Anomaly Detection Changes for Your Team
Network anomaly detection changes how quickly your team learns that something has gone wrong. Alerts come from behavior the platform has learned, so problems surface while they are still small.
Earlier detection. Deviations show up before end users report them.
Fewer blind spots. Metrics with daily and weekly cycles get watched across the whole cycle.
Quieter alert queues. Severity bands keep minor variation out of critical.
Faster root cause work. Anomalous metrics narrow where to look during an investigation.
Planned capacity. Forecasts show where bandwidth and device resources will run short.
Security signal. Traffic that breaks pattern gets flagged alongside performance issues.
Motadata ObserveOps runs anomaly detection as part of a full network monitoring solution, so detection, correlation, and response happen on one platform.
Ready to implement Network Anomaly Detection?
Discover how Motadata AIOps can help you monitor your infrastructure in real-time and respond to issues instantly.